
例えば100個の文章ファイルがあって、それを、機械学習、プログラミング、その他 で分けたい場合、下記のようになったとする。
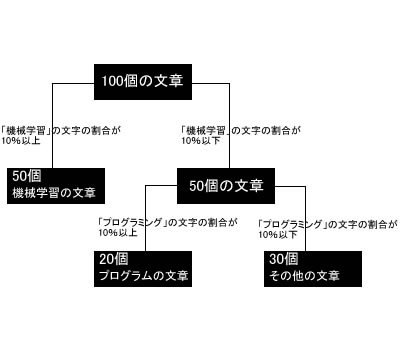
このように分類化させることで、新しい文書が作成されたときに、その文書がどのカテゴリーに属するかを予測させることができる。
分類わけを決定させる構造が「木」のようになるので、決定木と呼ばれる。
・決定木のパラメーター
決定木を効率的に行うには、枝分かれの数を少なくする必要がある。そのためには、最も効果的な「質問」をする。
最も効果的な「質問」を設定するためにジニ係数とエントロピーという概念がある。
ジニ係数
不平等さを示す指標。0-1の間の値をとり0で平等
ジニ係数が最も低下するように分類する
エントロピー
情報量を図る指標
エントロピーに基づくインフォメーションゲイン比より分類
sckitでは、ジニ係数がデフォルトで設定される。
・sckitでの決定木の実装。
※features_train、 labels_train、features_test は別で定義済。
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf.fit(features_train, labels_train)
predict = clf.predict(features_test)
※重要なパラメーターとして、「min_samples_split」もある。デフォルトは2だけど、50ぐらいで設定して精度を比較するのも重要。
パラーメーターやメソッドの詳細はこちら。